What is EchoMimicV2?
In this blog, we explore EchoMimicV2, showcasing how it brings portraits to life with state-of-the-art audio-driven animation. We cover how it works, its strengths and limitations, and how to run it on Sieve.

by Akshara Soman
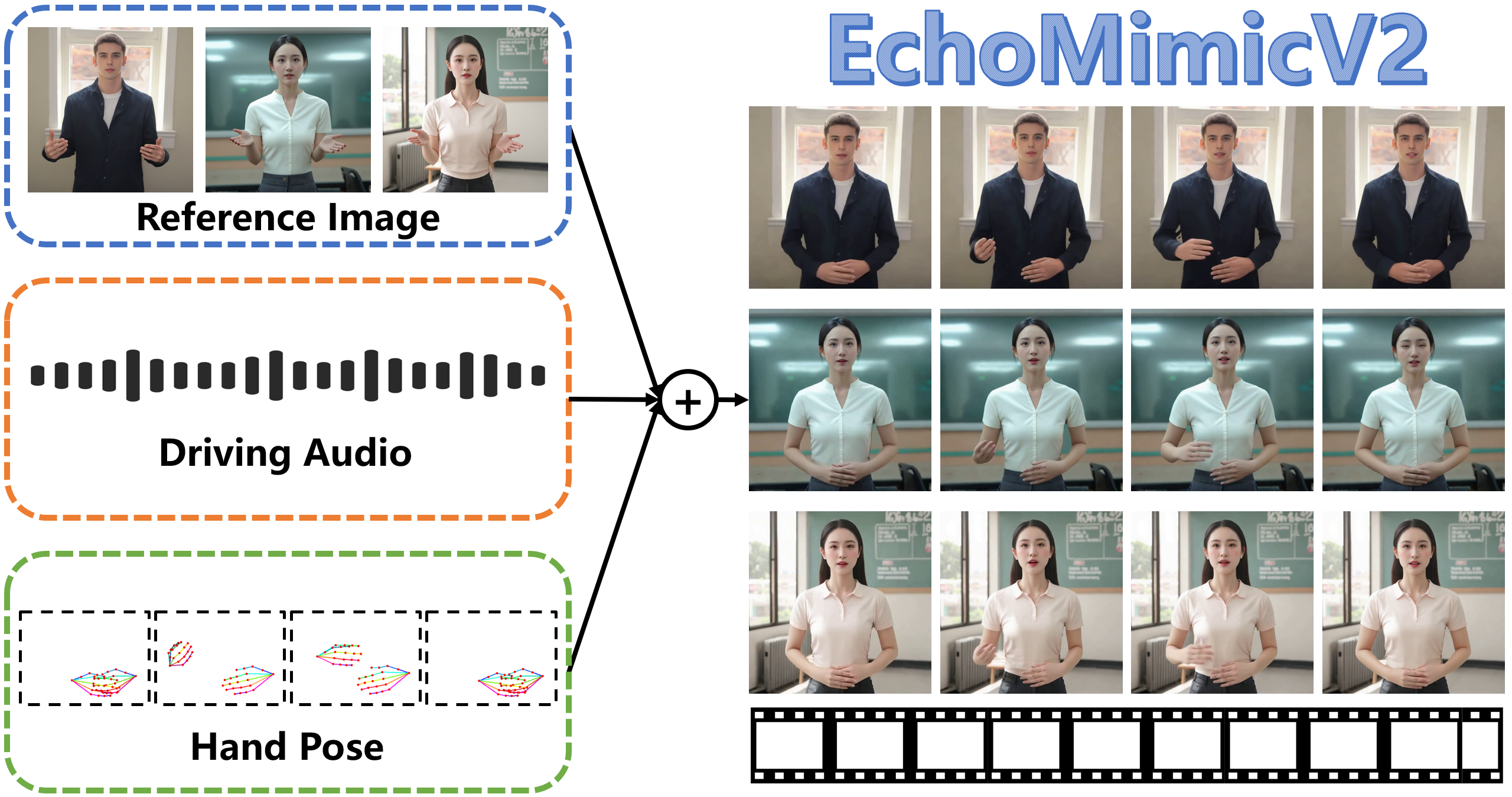
EchoMimicV2 is a state-of-the-art AI model that transforms static portraits into dynamic animations synchronized with audio input. It addresses the growing need for realistic digital avatars by converting still images into expressive, talking characters with natural facial movements and gestures.
EchoMimicV2 utilizes a reference image, an audio clip, and a sequence of hand pose to generate a high-quality animation video, ensuring coherence between audio content and half-body movements.
A sample half-body animation video generated by EchoMimicV2 model with Chinese driving audio. ©https://antgroup.github.io/ai/echomimic_v2/
How Does EchoMimicV2 Work?
EchoMimicV2 simplifies portrait animation by reducing dependency on complex pose mapping. Here's how it works:
Core Architecture
- Latent Diffusion Model (LDM): Converts input images into an efficient latent representation using VAE encoding
- ReferenceNet: Maintains visual consistency by extracting and integrating reference image features
Audio-Pose Dynamic Harmonization (APDH)
- Pose Sampling: Begins training with complete pose data and gradually removes less critical pose details to let audio take a dominant role.
- Audio Diffusion: Gradually enhances audio's control to drive lip movements, facial expressions, and coordinate gestures, emphasizing hand movements.
Head Partial Attention (HPA) for Data Augmentation
- Augments datasets using headshot images to address the scarcity of half-body training data.
Phase-Specific Denoising Loss (PhD Loss)
Optimizes animation quality in three stages:
- Captures movement and contours.
- Refines facial details and expressions
- Enhances low-level attributes like color and clarity
Temporal Cross-Attention
- Ensures motion smoothness across animation frames.
This streamlined framework ensures EchoMimicV2 produces state-of-the-art animations while reducing computational complexity and dependencies on detailed pose conditions.
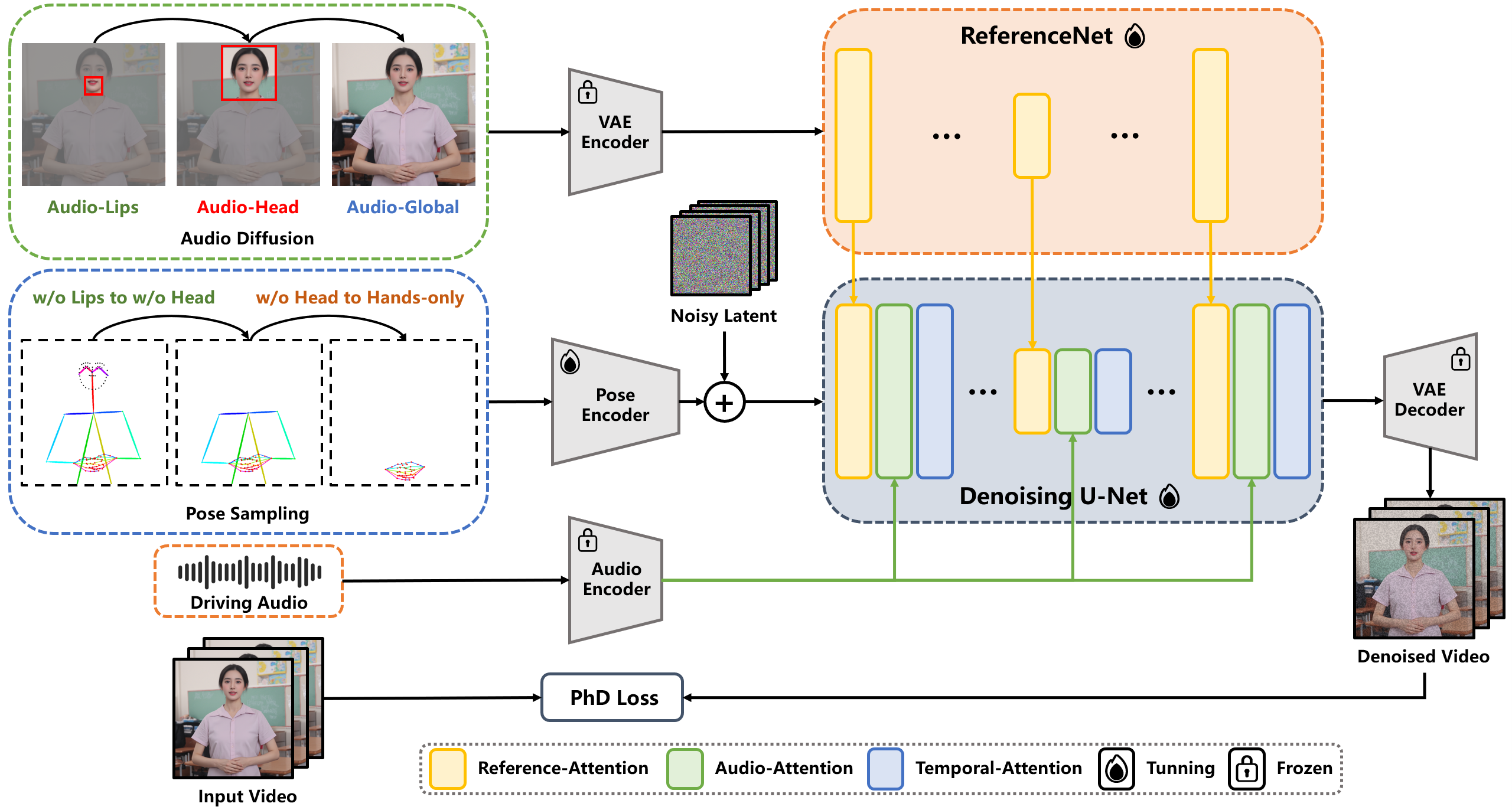 The overall pipeline of EchoMimicV2. © https://arxiv.org/pdf/2411.10061
The overall pipeline of EchoMimicV2. © https://arxiv.org/pdf/2411.10061
Performance
Like most AI models, EchoMimicV2 has its strengths and limitations. Let's explore where it excels and where it encounters challenges.
Benefits
- Exceptional Realism: Produces natural facial expressions and body movements that create compelling animations
- Streamlined Input Process: Minimizes reliance on complex pose maps by focusing on audio-driven animation
- Efficient Data Usage: Leverages Head Partial Attention (HPA) to maximize limited training data
- Versatile Applications: Powers virtual avatars, content creation, educational tools, and customer service interfaces
Limitations
- Image Format Requirements: Best results require properly cropped half-body images
- Gesture Accuracy: While general movements appear natural, precise hand gestures may lack detail
Running EchoMimic on Sieve
Currently, EchoMimicV1 (released July 2024) is available on Sieve, enabling users to create lifelike animations effortlessly. The enhanced EchoMimicV2 (released November 2024) will be available soon.
To get started with EchoMimic on Sieve, create a Sieve account and install the Python package. Here’s a simple code snippet to run EchoMimic:
import sieve
source_image = sieve.File("some_portrait.jpg")
driving_audio = sieve.File("some_audio.mp3")
echomimic = sieve.function.get("sieve/echomimic")
output = echomimic.run(source_image, driving_audio)
print(output)Alternatively, you can run EchoMimic function directly from the Sieve webpage after signing up. Sieve offers $20 in free credits for new users, making it easy to experiment without any upfront cost.
Here is a sample output video generated using the EchoMimic function in Sieve:
Conclusion
EchoMimicV2 is a great tool for creating realistic, audio-driven portrait animations. Its advanced technology opens doors for diverse applications, from personalized avatars to immersive storytelling. While the model demands some computational resources and technical setup, platforms like Sieve make it accessible and user-friendly for developers.
Resources
- EchoMimicV2 GitHub Repository
- EchoMimicV2 Project Page
- For inspiration, check out this blog: Transform Youtube videos into conversational avatars