

We’ve developed a new zero-shot lipsync pipeline designed to preserve more realism than existing solutions. Unlike traditional avatar or trained approaches, our pipeline is built to perform in any condition with zero training process required.
Today, we are releasing the initial version of this pipeline as a pre-built Sieve app. This is the first version so expect improvements over time. Alongside this release, we’re also going into the technical details of the pipeline so developers can work to reproduce and improve it themselves. In a couple weeks, we plan to release an open-core pipeline that developers can also tinker with using Sieve.
Avatars vs Zero-shot Lipsync
Companies like HeyGen and Synthesia are pioneers in the avatar space. An avatar typically requires a user to upload about ~2 minutes of training footage which is then used to mimic that same person in the exact same pose and environment, while allowing them to say anything. The benefit of this approach is the seemingly greater fidelity although the tradeoff that’s being made is inflexibility in working in all sorts of environments, forcing users to upload “training content”, and naturally being on the upper end of cost compared to other solutions. These approaches are typically NERF-based (you can find a whole list of papers here).

Lipsync, on the other hand, involves modifying only a specific part of the face—typically the lips or the lower half—to make it appear as though the person is saying something new. Performing lipsync in a zero-shot manner means doing so without any training process. This approach is advantageous because it allows for more cost-effective application in highly dynamic environments and reduces the need for end-users to upload training content. However, the tradeoff is a reduction in quality and emotional realism, as other facial features may not move naturally in sync with the spoken words.
Most of the historically popular approaches here are open-source with VideoReTalking and MuseTalk being more recent, popular options.
SieveSync Results
While SieveSync works in many dynamic scenarios, it tends to work best when the face is an arms distance from the camera and facing forward. Here are some examples of SieveSync side-by-side with other open-source solutions.
MuseTalk
Video Retalking
SieveSync
More SieveSync Examples
How it Works
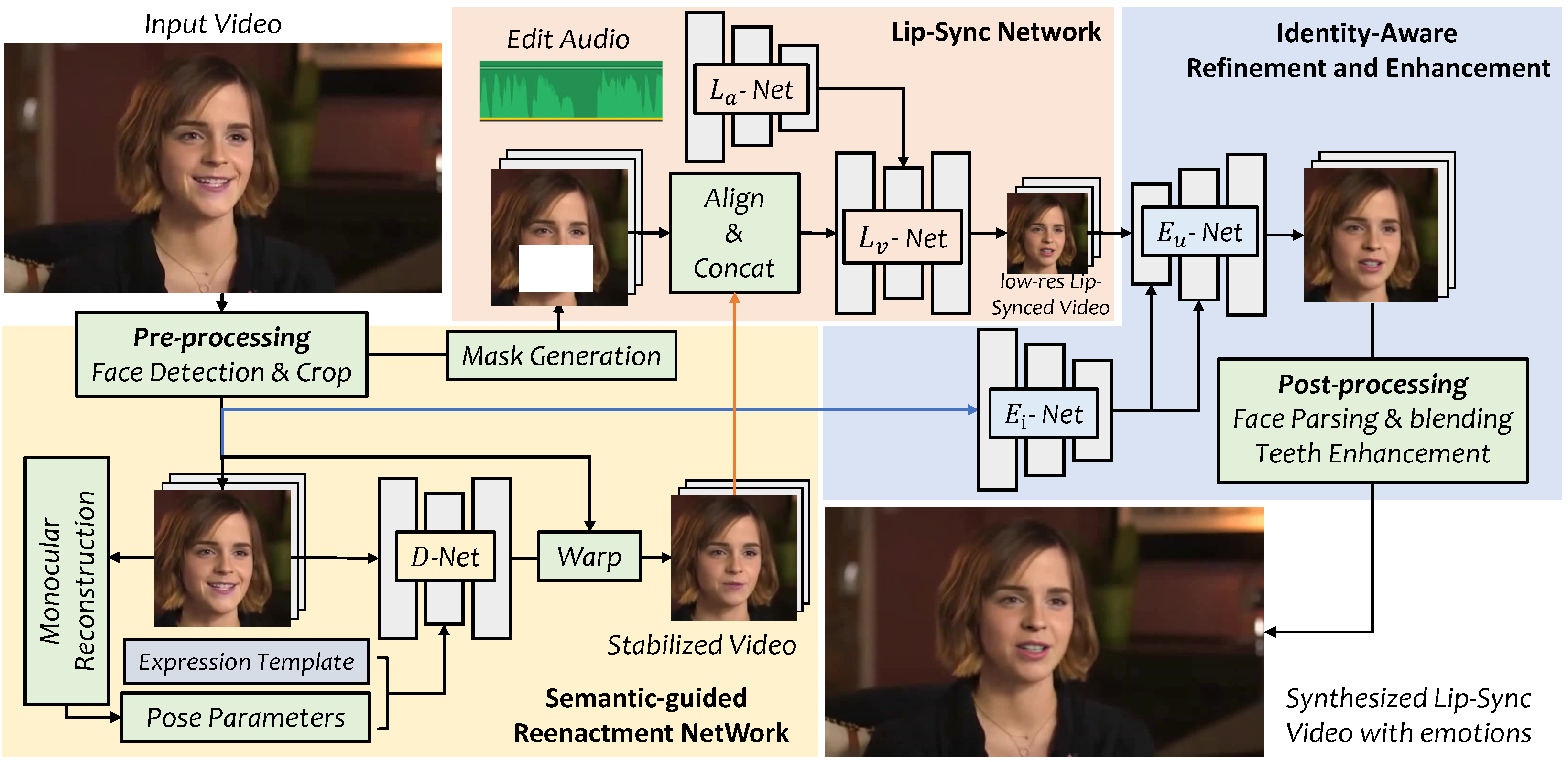
SieveSync is a pipeline built on top of MuseTalk, LivePortrait, and CodeFormer. MuseTalk is a great zero-shot lipsync model that was released earlier this year. We did some optimization work around it that made it 40% faster and wrote about some of its most common flaws. LivePortrait is an image animation and facial retargeting model that shows powerful facial manipulation capabilities. CodeFormer is an older model released in 2022 that can perform face restoration on images.
We took these three models and built a pipeline around them that produces higher quality lipsync results than any individual lipsync model is able to.
Facial alignment using MediaPipe
One of the key challenges in lipsync is dealing with variations in head orientation and facial expressions in source videos. MuseTalk, our chosen lipsync model, performs best when the input face is upright and neutral. To create these ideal conditions, we developed a custom alignment algorithm using MediaPipe FaceMesh to accurately detect facial landmarks. By creating a vector from the mouth to the region between the eyes, we calculated the necessary matrix transformations to orient this vector vertically. Treating each frame as a matrix, we applied OpenCV's warpPerspective function for rapid image transformations, effectively "straightening" tilted faces.

This alignment process not only standardized the head position across frames but also minimized discrepancies that could confuse the lipsync model. By storing these transformations frame-by-frame, we ensured that we could accurately reverse them later, preserving the original video's context while benefiting from the improved alignment during lipsync processing.
Source
Aligned
Minimizing Source Noise with LivePortrait Retargeting
Even with alignment, residual mouth movements in the source video can interfere with the lipsync process, leading to less accurate or less natural results. To address this, we utilized LivePortrait's retargeting capabilities to neutralize unintended lip movements. By effectively "closing" the mouth in each frame, we provided MuseTalk with a neutral canvas, allowing it to focus solely on generating the desired lip movements based on the audio input.
This step was crucial because it eliminated conflicting visual information that could degrade the quality of the lipsync. Our team optimized this process by parallelizing tasks and asynchronously preprocessing and postprocessing frames. By batching preprocessed frames and leveraging GPU acceleration, we maintained constant memory usage regardless of video length, significantly improving processing speed without compromising quality.
Enhancing Expressiveness with MuseTalk and CodeFormer
With the input video optimally aligned and neutralized, MuseTalk could perform lipsync with greater accuracy and expressiveness.
We optimized MuseTalk's performance by enabling batched inference and refining landmark extraction, allowing it to handle videos of arbitrary length efficiently. Additionally, we implemented a custom silence detection algorithm that dynamically adjusted mouth movements, resulting in more natural and emotive synchronization. An override input was also introduced to modulate the intensity of lip movements, giving us control over the expressiveness of the output. Read more about these optimizations here.
Post-processing with CodeFormer further enhanced the visual quality of the lipsynced video. We developed a custom blend ratio algorithm that adjusted CodeFormer's influence based on the size of the face in each frame. This dynamic approach ensured that facial details were refined without making the face appear unnatural. By applying linear interpolation with defined maximum and minimum thresholds, we balanced the restoration process to maintain realism.
Without CodeFormer
With CodeFormer
Trying the app on Sieve
Sieve’s platform exposes a simple interface for running lipsync which you can run via a playground or through a simple API. SieveSync is enabled by default and prices at $0.50 / min of generated video, pay-as-you-go.
Our open-core release
We plan to launch an open-source repository in a few weeks. We use the word open-core here because we plan to release a repository with all the pipeline logic you need to run the application on Sieve. This is because Sieve has the most optimized versions of these models & the infrastructure that would allow you to reproduce the exact same quality, cost, and speed with minimal engineer work.
However in theory, this would allow you (if you wanted) to switch out Sieve components for self-hosted components which you could self-host — assuming you want to go through the legwork of optimizing all the pieces and re-engineering the small quality improvements we’ve done to each of the components.
It’ll also highlight a few other optimizations we didn’t touch on in this blog including denoising the audio prior to lipsync using Sieve’s audio enhance app and parallelizing various components of the pipeline like LivePortrait retargeted, using Sieve’s burst compute infrastructure. Stay tuned for this release!
Conclusion
We’re excited by what video pipelines enable, especially if you optimize the hell out of them. New open-source models are bound to drop and our team plans to squeeze every little bit out of the last-mile of engineering that can be done to push on quality, cost, and speed of these solutions. Email us at contact@sievedata.com or join our Discord if you’re a developer interested in lipsync, we’d be happy to share more!