
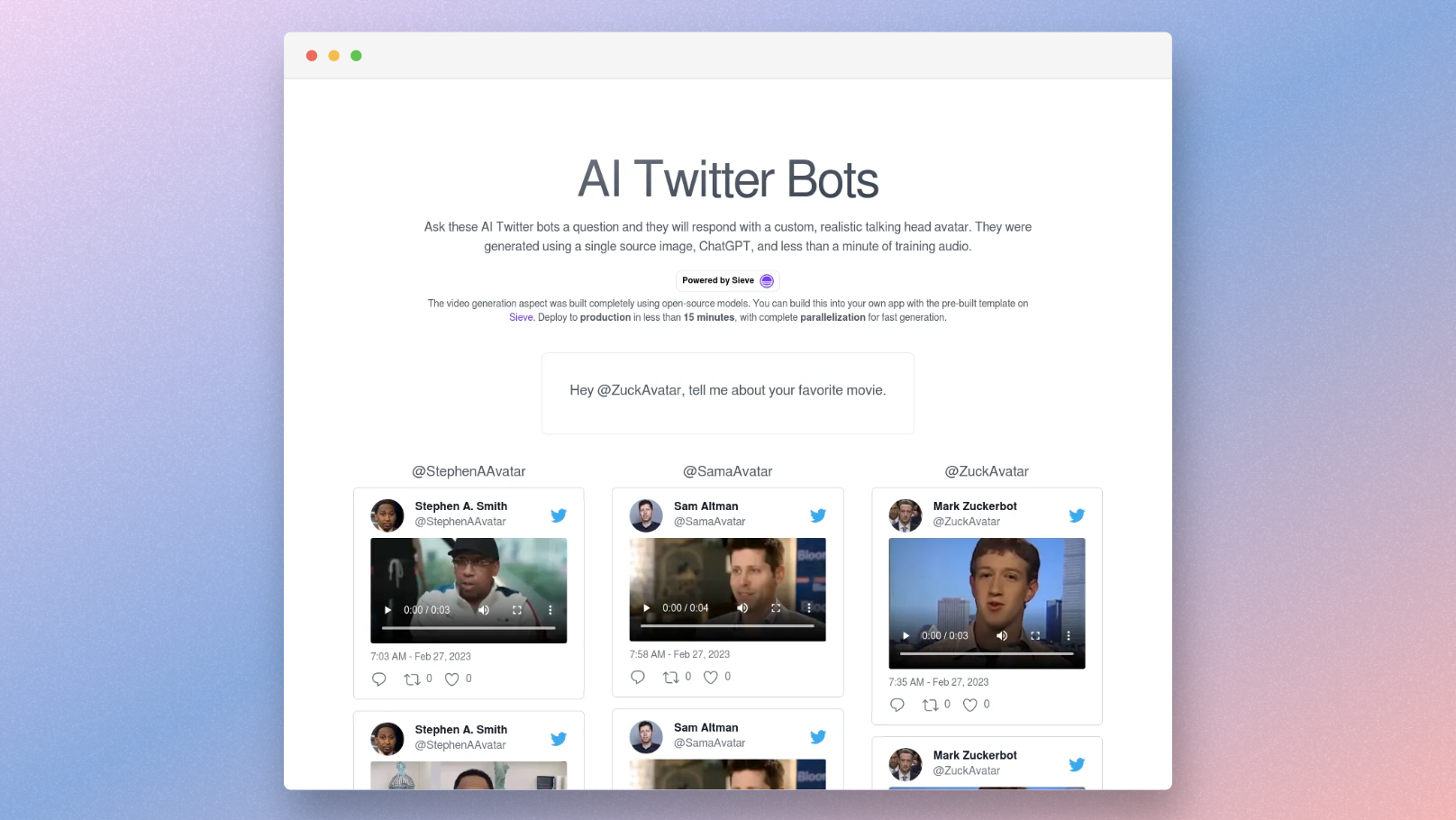
This blog showcases a suite of various pipelines available in the Sieve toolkit for creating realistic AI avatar videos. These pipelines leverage both open-source models and optimized proprietary backends, offering a variety of approaches tailored to diverse use cases.
- Portrait Avatar pipeline: Transforms a high-quality 2D image into a lifelike talking avatar using audio inputs, ideal for educational content, marketing videos, and podcasts.
- LivePortrait pipeline: Utilizes video-driven animation to bring static images to life by applying motion from driving videos, enhancing media and interactive content.
- Lipsync pipeline: Focuses on precise lip synchronization by aligning speech with facial movements, powered by multiple backends like SieveSync, MuseTalk, and Video Retalking.
Each pipeline offers unique strengths, from fine-tuned customization and performance optimization to seamless integrations for developers. In this blog, we explore what each of these pipelines does, their key use cases, and their strengths and limitations.
Let’s dive into each approach in detail!
Portrait Avatar Pipeline
This pipeline transforms a high-quality 2D image into a video of a realistic AI avatar speaking provided audio. It's generally best for use cases that require fast, flexible avatar generation in comparison to a one that requires 2-3 minutes of training video.
Strengths
- Generates high-quality talking avatars from static images.
- Offers three robust backends, including proprietary options from leading research companies and one open-source model.
- Customization: Supports multiple aspect ratios and offers optional CodeFormer face restoration for improved video clarity.
- Easy to integrate into workflows for single-person visuals.
Weaknesses
- Limited to static images; less effective for videos or complex gestures.
- Works best with clean, high-quality inputs featuring a single person.
More details on available backends
- Hedra (default): Default backend for versatile, lifelike talking heads.
- Powered by the Character-2 foundation model.
- Generates highly realistic talking heads across diverse styles.
- Infinity AI
- Produces expressive avatars with diverse styles and angles using its own video foundation model.
- Allows developers to customize avatar expressiveness and video resolution.
- EchoMimic
- Based on the open-source EchoMimicV1 model.
- Provides stable and expressive talking heads in a square crop format.
- Sieve's optimized deployment ensures enhanced performance for reliable results.
Learn more
LivePortrait Pipeline
LivePortrait on Sieve is an optimized implementation of the open-source model best for matching motion between a target image and a driving motion video. This is most useful in scenarios where you're trying to match motion of more than just the lips and have a separate video of a person acting that out.
How it works
- Uses an implicit-keypoint-driven framework to animate portraits without the heavy processing of diffusion-based methods.
- Two-stage animation process for refined motion control:
- Stage 1: Motion transformation ensures accurate animation flow.
- Stage 2: Expression control with lightweight multi-layer perceptron (MLP) modules allows fine-tuning of key facial features like eyes and lips.
- Enhanced by Sieve with significant optimizations for performance and quality.
Best for
- Photo Animation: Animate static images with motion data for interactive AI avatars, media, and entertainment projects.
- Video Animation: Integrate expressions and poses into source videos for content creation, VR, and video editing workflows.
Strengths
- Efficiently animates static images and videos with low computational overhead.
- Provides fine-tuning options for precise control over facial features like eyes and lips.
- Ideal for photo-to-video animations and video-driven workflows in interactive content.
- Optimized for high performance, making it suitable for real-world applications.
Weaknesses
- Motion quality is dependent on the driving video.
- Less expressive compared to diffusion-based tools like EchoMimic.
Learn more
Lipsync Pipeline
This pipeline aligns lip movements in a video with provided audio to create natural and synchronized talking animations. While similar to AI avatar generation, which animates facial expressions and gestures from a static image or video, lip-syncing specifically focuses on achieving precise synchronization of the lips with speech and natively works on input videos. This is ideal for creating realistic talking head avatars and having precise control over when in an original video the lips are manipulated.
Strengths
- Real-time performance with frame rates up to 30+ FPS.
- Flexible backends for varying project requirements.
- Enhanced face restoration ensures high-quality output.
Weaknesses
- Primarily focuses on lip movements; less suited for full facial animation.
- Sensitive to videos with excessive motion or complex edits.
More details on available backends
- SieveSync
- Combines proprietary alignment techniques with the open-source MuseTalk and LivePortrait models for faster inference and better audio alignment.
- Works best with videos that have minimal scene changes.
- MuseTalk
- An optimized version of the open-source MuseTalk model for real-time, high-quality lip-syncing.
- Runs 40% faster than the base implementation.
- Video Retalking
- Built on the open-source Video Retalking model, this backend excels in lip-syncing and face restoration using GPEN and GFPGAN.
Learn More
Use Cases of AI Avatars
- Media and Entertainment: Create talking head videos for ads, explainer content, or movies.
- Interactive Experiences: Integrate responsive avatars into VR and video games for immersive interactions.
- Synthetic Data Generation: Generate animations for training machine learning models in computer vision.
- Augmented Reality (AR): Enhance AR filters with realistic lip-syncing and expressive animations.
- Education and Training: Use avatars in virtual classrooms and simulations to improve engagement.
- Social Media and Marketing: Design eye-catching AI avatars for social media campaigns and branding.
Note on Ethical Usage
Lipsync and avatar technologies come with social risks, such as potential misuse in creating deepfakes. Sieve prioritizes ethical usage by embedding watermarks in generated results and encourages adherence to responsible practices. For detailed guidelines, refer to the pipeline readme files.
Why Choose Sieve’s AI Avatar Pipelines?
Designed with developers in mind, Sieve’s AI avatar pipelines are built to seamlessly integrate into production environments, offering:
- Production-Grade APIs: High-performance APIs optimized for speed, cost-efficiency, and reliability in real-world applications.
- Comprehensive Solutions: A versatile toolkit combining multiple pipelines in one platform, enabling flexibility across various use cases.
- Effortless Integration: Developer-friendly design for smooth adoption into existing workflows, reducing time-to-market.
- Scalable Infrastructure: Robust pipelines that handle large-scale projects while maintaining high-quality output.
Connect with like-minded developers in our Discord community or email us at contact@sievedata.com for personalized support. You can also book a demo with our team to discover how our pipelines can streamline your workflow and transform your projects!