

Today we’re excited to introduce Portrait Avatars on Sieve, opening up easy API access to developers looking to generate talking head videos from a single image and an audio sample. This comes alongside partnerships with leading research companies in the domain including Hedra Labs and Infinity AI, as well as optimized deployments of open models like EchoMimic.
What are Portrait Avatars?
There are three main approaches to creating realistic avatars: full avatar synthesis, lipsync modification, and portrait avatars.
Full avatar synthesis, used by companies like HeyGen and Synthesia, requires a couple of minutes of user footage to create a lifelike replica that can speak in the same pose and environment. While this offers high fidelity, it demands training footage and is generally more costly.
![]()
Lipsync modification, on the other hand, focuses on altering only the mouth to produce speech in a zero-shot manner, reducing the need for pre-existing user content and providing flexibility across settings, though with less natural facial expressiveness.
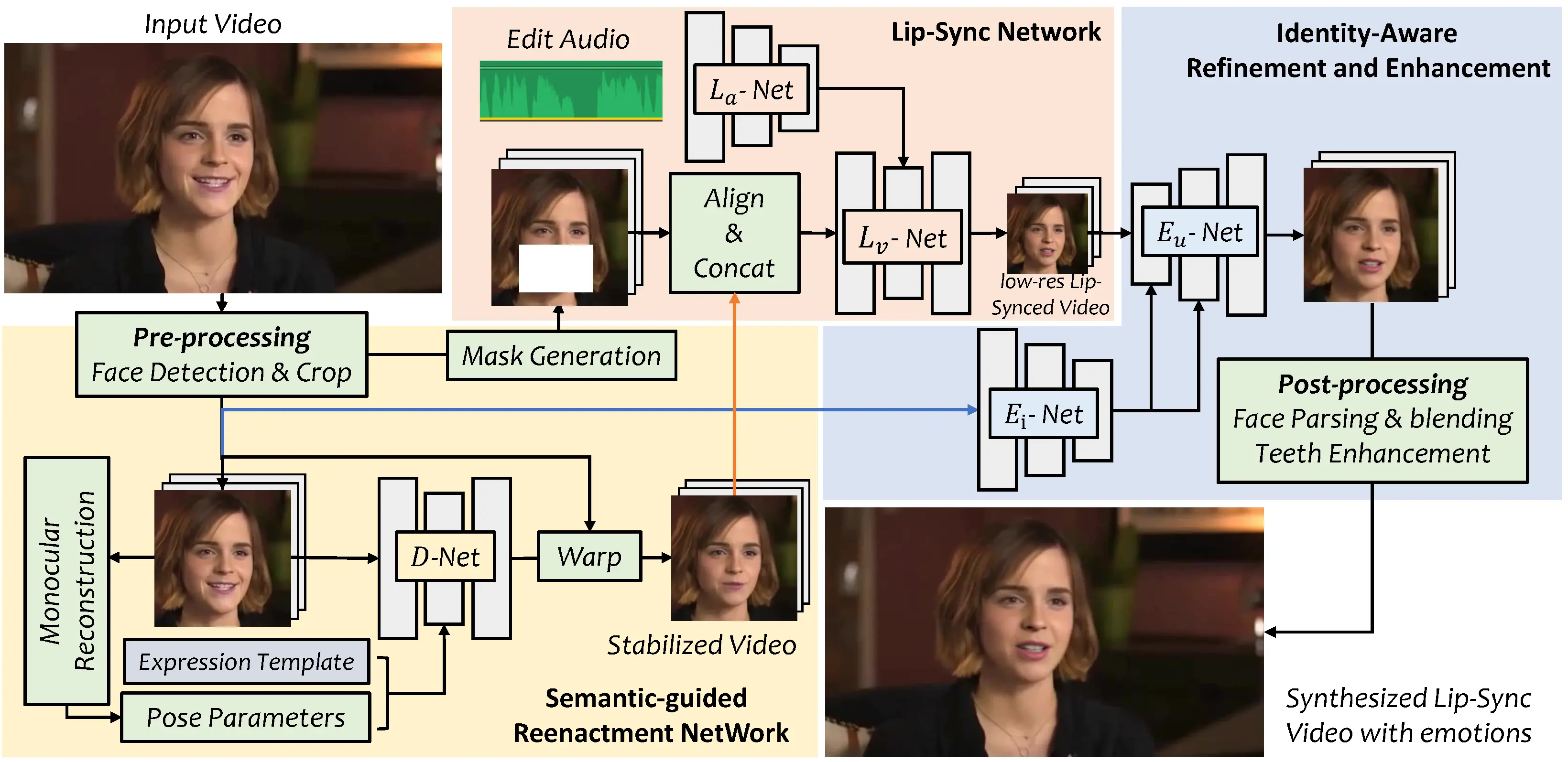
Finally, portrait avatar models like EchoMimic combine the benefits of fidelity and adaptability, allowing users to achieve talking head avatars that feature full face movement, from a single image and audio. These avatars are able to capture tone and emotion in facial expressions without training.
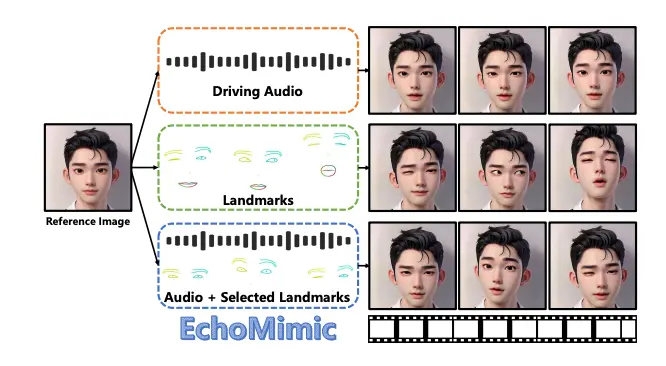
Sieve’s Portrait Avatar Pipeline
The sieve/portrait-avatar function generates a dynamic avatar from a static source image and driving audio, allowing users to create a realistic talking head representation. With multiple model options, this app provides users with flexibility, enhanced quality, and customizable parameters to fit various needs.
- Best Models in One Place
- Access three powerful backends — Hedra (default), Infinity AI, and EchoMimic — in one place.
- Each model offers unique qualities, balancing realism, expressiveness, and stability.
- Customization and Enhancement Options
- Fine-tune the avatar's expressiveness, aspect ratio, and resolution to match the desired output.
- For an added cost, apply face restoration to improve clarity.
- Flexible Output Settings
- Adjust video resolution, aspect ratio, and cropping preferences based on the model and output requirements.
- Model-specific parameters provide granular control over aspects like expressiveness (Infinity AI) and head cropping.
- Ethical Safeguards
- Watermarks and visual artifacts are included to prevent misuse as deepfakes.
- Guidelines promote responsible use to mitigate social risks associated with avatar and lipsync generation technology
Conclusion
Talking head videos are becoming a powerful way humans communicate online, and we’re excited to make Sieve the best place to generate them all. To use Sieve, go sign up for an account here and get $20 in free credit. We’re excited to see what you build.