

MuseTalk is an open-source lip synchronization model that was released by the Tencent Music Entertainment Lyra Lab in April 2024. As of late 2024, it’s considered state-of-the-art in terms of openly available zero-shot lipsyncing models. It’s also available under the MIT License, which makes it usable both academically and commercially. Below is a video of MuseTalk being used to dub content to English.
How does it work?
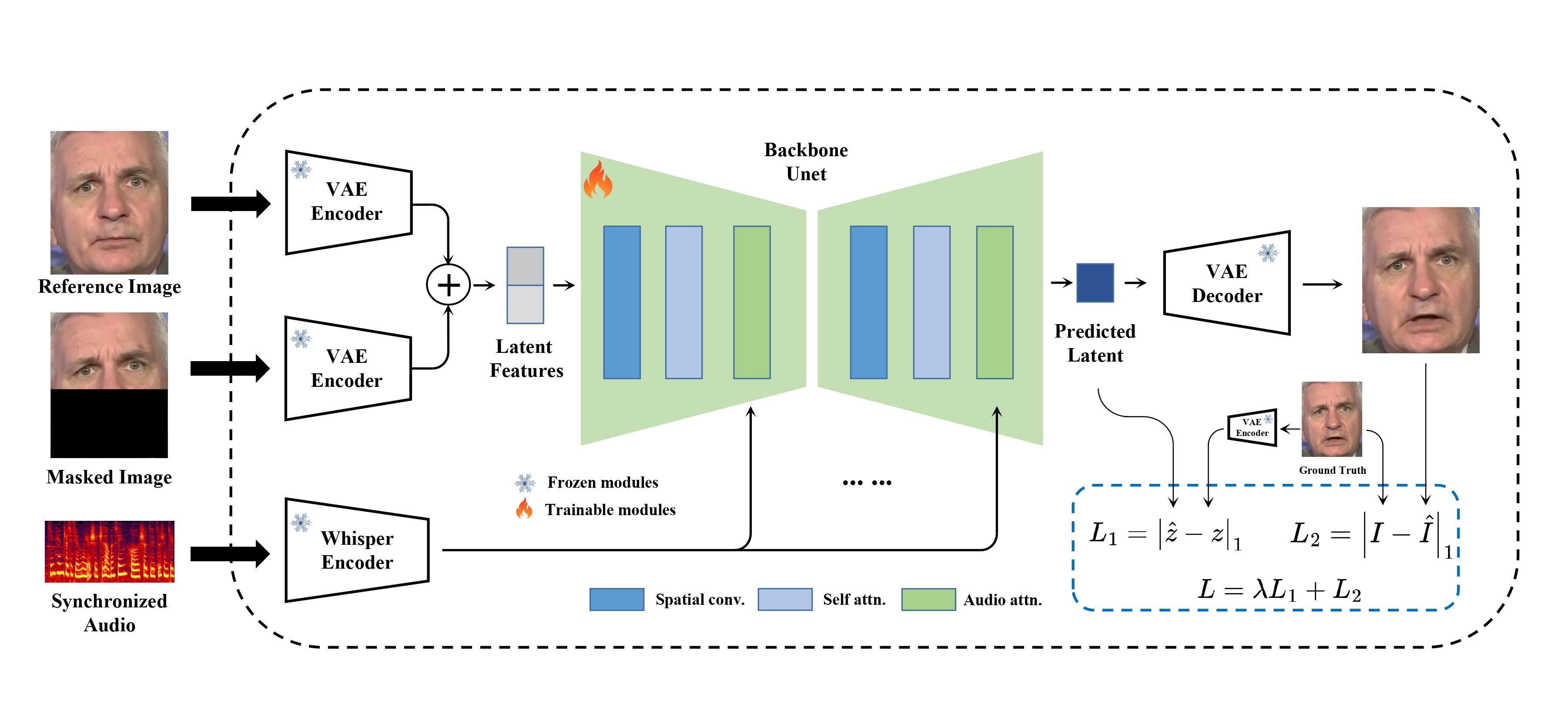
While the authors have yet to release a technical post, we have a general understanding of how it works from the codebase and the repository description. MuseTalk is able to modify an unseen face according to a provided audio with a face region of 256 x 256.
It makes use of Whisper-tiny's audio features to perform the facial modifications. The architecture of the generation network is borrowed from the UNet of stable-diffusion-v1-4 where audio embeddings were fused with the image embeddings using cross-attention.
The model was trained on the HDTF dataset which contains about 16 hours of high quality videos of speakers, allowing consistent generations and minimal loss of detail in the face region. While the architecture is similar to stable diffusion and the data processing steps have some overlap, MuseTalk is not a diffusion model, but rather an inpainting model that inpaints the latent space with a single step.
Performance
As with most AI models, MuseTalk comes with its own caveats. Lets review where it performs well and where it doesn’t.
Pros
The two most popular open-source lipsyncing models prior to MuseTalk were VideoReTalking (2022) and Wav2Lip (2020). The most common issue historically has been that the core models alone weren’t yielding high enough resolution or realism which meant the need to use upscalers like GFPGAN to restore the generated results to higher levels of fidelity. This however meant longer processing times and fake-looking results due to the “cartoon”-ish nature of the outputs produced by various upscalers.
Let’s compare a sample video that was lipsynced from English to Spanish with MuseTalk And VideoReTalking side-by-side.
What you’ll generally notice is that MuseTalk, without any upscalers, is able to generate better realism around the mouth region whereas VideoReTalking (which relies on various upscalers) ends up producing results that look a bit more fake. This is the biggest advantage of MuseTalk compared to prior models.
Cons
While the model is good at keeping facial structure and realism, it struggles in a couple areas.
- Audio Silences: Because the model uses Whisper features (which tends to have hallucination problems), a person might appear to be moving their lips even in mostly silent portions of the audio.
- Tooth Resolution: You’ll generally notice a sort of blur in the tooth area, especially if faces are closeup.
- Lipsync Trueness: The end-goal of lipsync is the make the mouth look like it’s speaking the audio. At times (especially when the person’s face moves a ton or tilts), the model will seemingly output lower face movements that don’t seem to resemble the target audio.
- Processing Time: While the model repository advertises itself as realtime, the problem arises from pre/post-processing which ends up taking 10x longer than the core model itself.
Running it on Sieve for improved quality and efficiency
Our team has spent some time working with this model to optimize a ton of low-hanging fruit when it comes to cost, quality, and speed. Specifically, we’ve resolved issues around audio silences and have made the model run 40% faster. Most of the speed gains come from Sieve's inference engine which optimizes the way we load, store, and save video frames through the MuseTalk pipeline. Because of these optimizations, the model is now priced cheaper than self-hosting on GCP at ~$0.14 / min of generated video! Let’s see how to get started with it.
Create a Sieve Account
Create a Sieve account by going here and grab your API key from the settings page.
Run the app
Sieve lets you run the model through the REST API, the Python client package, or the web interface. If you just want to try it out without code, you can use the web interface here.
Python Client
First make sure that you have the python package installed.
pip install sievedataNow log in with your API key. You can also set the SIEVE_API_KEY variable if you’re setting this up on a server.
sieve loginNow run the following code.
import sieve
musetalk = sieve.function.get("sieve/musetalk")
# you can change this path to a local path or a different URL
video_path = "https://storage.googleapis.com/sieve-public-data/musetalk-blog/elon_video.mp4"
audio_path = "https://storage.googleapis.com/sieve-public-data/musetalk-blog/elon_audio.mp3"
video = sieve.File(video_path)
audio = sieve.File(audio_path)
# to run this async, you can change .run to .push which will return a future
# once you get the future, you can call .result().path
output = musetalk.run(video, audio)
print(f"Output saved at {output.path}")REST API
Start by submitting a request via the API. This is a sample cURL request you can run after replacing YOUR_API_KEY. The request should return a job ID in the id field of the response.
curl "https://mango.sievedata.com/v2/push" \
-X POST \
-H "Content-Type: application/json" \
-H 'X-API-Key: YOUR_API_KEY' \
-d '{
"function": "sieve/musetalk",
"inputs": {
"video": {"url": "https://storage.googleapis.com/sieve-public-data/musetalk-blog/elon_video.mp4"},
"audio": {"url": "https://storage.googleapis.com/sieve-public-data/musetalk-blog/elon_audio.mp3"}
}
}'You may now poll for the request through this endpoint or have set a webhook on job push.
If you're looking to try this with other audio files, you could generate some new audios with Sieve's text to speech function.
Conclusion
Overall, MuseTalk is an extremely promising model that showcases the rapid improvements in open-source AI. We’re consistently looking to improve open-source models and build on top of them. If you’re looking to make something cool with this model, join our Discord and share what you’re building!