

Segment Anything Model 2 (SAM 2) is a new image and video segmentation model released just a few weeks ago by Meta. It builds on the original SAM as now being the first unified model that can segment objects across images and videos with the ability to take points, boxes, or masks as input.
The community excitement around it has been incredible, so today we’re excited to announce Sieve’s public SAM 2 function: Built for production and running over 2x as fast as other SAM 2 endpoints from cloud providers with no quality degradation.
SAM 2 vs SAM
Segment Anything was the first model in this series (released in April 2023) which primarily focused on image processing, specifically zero-shot segmentation. SAM 2 builds on this foundation to support video by treating images as single-frame videos. SAM 2 is also 6 times faster than SAM out-of-the-box, takes in more complex positive/negative point prompts, and was trained on a much more extensive dataset (SA-V) which means better performance. To learn more about these details, you can read the research paper here.
Use Cases
Native video support enables some new computer vision use cases that weren’t previously possible with SAM.
Video Creation
Being able to segment objects in videos means the ability to create interesting video effects, automate keypoint tracking for various animations, or use the masks as inputs to downstream video generation models that might generate something completely new.
One of our customers, Scenery, has been experimenting heavily with Sieve’s SAM 2 function to generate animation keyframes in their editor.
Sports Tracking
Another interesting use case is in sports tracking. The ability to track objects as tiny as a soccer ball or specific athletes amongst a large crowd — all without training a new model enables applications that likely weren't possible before unless you had an extremely talented in-house AI team.
Here's a tiny ball and a specific player being tracked in a soccer game.
Here's Usain Bolt being tracked in a race.
We even segmented all 10 players in a basketball game simultaneously!
Serving SAM 2
SAM 2 is a well-optimized video segmentation model. Clever tensor tricks, flash attention, and fast propagation algorithms mean SAM 2 can segment objects in your videos rapidly. However, building performant pipelines around SAM 2 has its own unique challenges. The good news is, at Sieve, we have tons of experience building optimized workflows around video use-cases, and our take on SAM 2 is no exception. Our benchmarks compared against SAM 2 deployments on other cloud platforms show that last-mile engineering can be just as important as a well-optimized model.
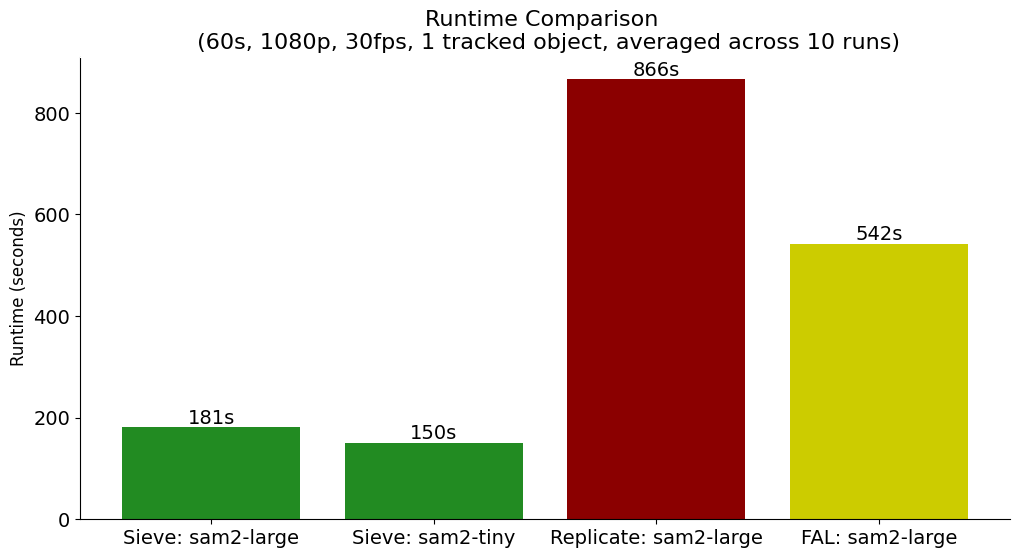
This benchmark was calculated by computing the average runtime across 10 runs on each platform, excluding queue time.
Pricing
Not only are we faster — we also offer SAM 2 for a lower price!
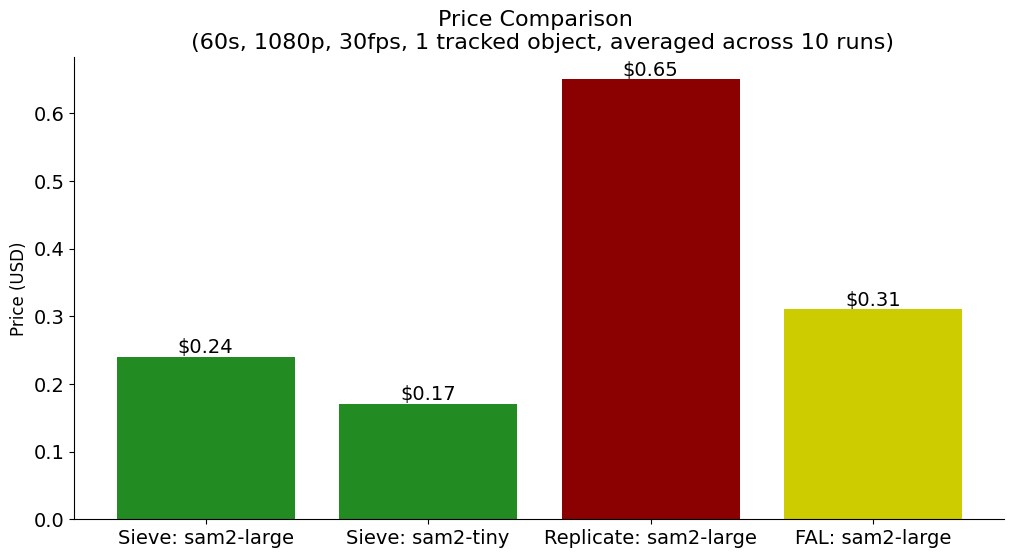
Pricing on Sieve is determined by the length of the input video in minutes (L), as well as the number of objects being tracked (O).
For model_type="large" we charge:
(0.216 * L) + (0.0288 * O * L)For model_type="tiny" we charge:
(0.144 * L) + (0.0288 * O * L)We assume the video frame rate is 30 fps. For more detailed pricing information, please refer to our SAM 2 README.
Running SAM 2 on Sieve
Prompting
SAM 2 is exposed as a Sieve function, which you can access via:
import sieve
sam2 = sieve.function.get("sieve/sam2")You can also try it via our UI here.
The main interface for controlling SAM 2 is prompts. A prompt in the context of SAM 2 is simply a labeling of a region of interest in an image. This region of interest can be annotated with a bounding box or a point with a positive or negative label.


Each prompt is associated with an object_id and a frame_index. Object ids make it possible to track multiple objects at once! Just be sure to give them unique ids.
prompts = [
{ # messi's ball
"frame_index": 0, # frame number to segment the object from
"object_id": 1, # id of the object to track
"points": [ # 2d array of x,y points corresponding to labels
[337.56451612903226, 505.56451612903226]
],
"labels": [1] # labels for each point (1 for positive, 0 for negative)
},
{ # neymar's ball
"frame_index": 0, # frame number to segment the object from
"object_id": 2, # id of the object to track
"points": [ # 2d array of x,y points corresponding to labels
[1036.9193548387095, 361.04838709677415]
],
"labels": [1] # labels for each point (1 for positive, 0 for negative)
}
]
It's important to note that SAM 2 can handle multiple prompts across different frames. This is useful in scenarios where a new object enters the frame, or for scene cuts.
prompts = [
{
"frame_index": 0, # prompt on first frame
"object_id": 1,
"points": [[1408,699],[1532,928]],
"labels": [1,1]
},
{
"frame_index": 450, # prompt on first frame after transition
"object_id": 1, # make sure to use the same object id!
"points": [[1075,506],[1013,579],[1137,579],[1133,517]],
"labels": [1,1,1,0]
}
]
Model Types
Meta actually released four distinct SAM 2 models, and we provide two of them on Sieve: tiny and large. Both models are excellent! The tiny model offers faster runtime at a lower cost, while the large model offers better quality at a steeper computation cost.
Submitting a SAM 2 job
Putting it all together, submitting a request to the SAM 2 endpoint looks something like this.
import sieve
sam2 = sieve.function.get("sieve/sam2")
debug_video, outputs = sam2.run(
file = sieve.File(path="path-to-your-video"),
# or consider sieve.File(url="url_of_your_video"),
model_type = "large" # choose "large" or "tiny"
prompts= [{
"frame_index": 0, # frame number to select an object from
"object_id": 1, # unique id of object to track
"points": [[300, 200]], # x, y point in frame (on object)
"labels": [1] # positive/negative label
}],
debug_masks = True
)Output Options
Our endpoint offers a variety of useful output options:
- Masks: The default output for SAM 2 is a mask for each frame-object pair.

- Pixel Confidences: Sometimes, having a more sophisticated signal than just a max can be useful — so we provide an option to generate a confidence score for each pixel in each frame. These are computed for all objects being tracked. Most of the time, confidences will be very close to 1, but you’ll see that SAM 2 will sometimes be less confident around the edges of an object or in periods of rapid movement.
- Bounding Box Tracking: Track the bounding box of each object for every frame. This can be especially useful when integrating with existing object detection pipelines.
{
"0": [
{
"object_id": 1,
"frame_index": 0,
"bbox": [445, 19, 531, 109]
}
],
"1": [
{
"object_id": 1,
"frame_index": 1,
"bbox": [446, 19, 531, 109]
}
],
"2": [
{
"object_id": 1,
"frame_index": 2,
"bbox": [447, 18, 533, 109]
}
],
...
}- Debug Masks: This option allows for rendering the segmentation masks over the original video. This provides an easy way to visualize the mask accuracy and separation between different masked objects. Many of the visualizations you’ve seen in this article were generated with this option.
- Preview Mode: Sometimes it can be useful to visualize the effects of prompts prior to segmenting your video. Setting
preview=Truewill generate annotated segmentation visualizations for each frame prompted. This is a great way to make sure your SAM 2 prompts are working as intended.
prompts = [
{
"points": [[460, 50],[460,200]],
"labels": [1,0],
"object_id": 1,
"frame_index": 0
}
]

For more on these options, visit our readme page or check out our Google Colab demo.
The demo notebook includes a full walkthrough of each of the output options and includes a cool visualization tool we built to help construct prompts.
What’s Next
We’ve had a lot of fun prompting SAM 2 since its release, and we think you will too — we can’t wait to see all the amazing things the computer vision community will build with SAM 2!
When you build something awesome, make sure to tag us at @sievedata so we can take a look! Also make sure to give us a follow, we’re working on even more awesome features and pipelines to allow developers to harness the power of SAM 2 that we plan to announce in the coming weeks — stay tuned!